Definition
A data structure is a method of storing and organizing data in a computer so that it can be accessed and modified efficiently. It is not only used for organizing data but also plays a key role in processing, retrieving, and storing it.
There are both basic and advanced types of data structures, and they are fundamental to almost every software system or application. Therefore, a solid understanding of data structures is essential.
Data structures enable the efficient management of large volumes of data, which is essential for tasks such as managing large databases and powering internet search indexing systems.
They are also crucial for building fast and effective algorithms. By helping organize and manage data, data structures reduce complexity and improve performance.
Classification of Data Structures
-
Linear Data Structure: In a linear data structure, data elements are arranged in a sequential manner. Each element is connected to its adjacent elements, forming a linear sequence.
Examples: Arrays, Stacks, Queues, Linked Lists. -
Static Data Structure: A static data structure has a fixed size determined at the time of declaration. Accessing elements in a static structure is generally straightforward.
Example: Array. -
Dynamic Data Structure: A dynamic data structure does not have a predefined size. It can grow or shrink during runtime, which can lead to more efficient memory usage.
Examples: Linked Lists, Stacks, Queues. -
Non-Linear Data Structure: In non-linear data structures, elements are not arranged in a sequential order. As a result, it’s not possible to traverse all elements in a single pass.
Examples: Trees, Graphs.
In computer science, data structures are generally categorized into two main types:
-
Primitive Data Structures: These are the basic structures provided by programming languages to represent simple values, such as integers, floating-point numbers, characters, and booleans.
-
Abstract Data Structures: These are more complex structures built using primitive data types. They offer specialized operations and are designed to solve more complex problems efficiently.
Common examples include arrays, linked lists, stacks, queues, trees, and graphs.
Primitive and Derived Data Types
Primitive data types are the fundamental, built-in types that serve as the foundation for creating more complex data structures. They directly represent single values and typically do not have associated methods. Common primitive data types include:
- Integer (int): Represents whole numbers.
- Floating-point (float, double): Represents numbers with decimal points.
- Character (char): Represents single characters.
- Boolean (bool): Represents truth values (
trueorfalse). - Void (void): Represents the absence of a value.
#include <iostream>
using namespace std;
int main()
{
int a = 7;
float b = 7.0;
double c = 7.0003;
char d = 'E';
cout<<"Integer value is = "<< a
<<"\nFloat value is = "<< b
<<"\nDouble value is = "<< c
<<"\nChar value is = "<< d <<endl;
}Output
Integer value is = 7
Float value is = 7
Double value is = 7.0003
Char value is = EDerived data types are formed by combining or modifying primitive types. They can represent multiple values and often include associated operations or methods. Common derived data types include:
- Arrays: Ordered collections of elements of the same type.
- Pointers: Variables that store memory addresses, used to indirectly access other variables.
- Structures: Groups of variables (which may be of different types) under a single name.
- Unions: Similar to structures, but all members share the same memory location.
- Functions: Reusable blocks of code designed to perform specific tasks.
- References: Aliases for existing variables, allowing indirect access.
#include <iostream>
using namespace std;
int main() {
int variable = 7;
int* pointr;
pointr = &variable;
cout << "Value of variable = " << variable;
cout << "\nValue at *pointer = " << *pointr;
return 0;
}Output
Value of variable = 7
Value at *pointer = 7Difference Between Primitive and Derived Data Types
| Feature | Primitive Data Types | Derived Data Types |
|---|---|---|
| Definition | Fundamental, built-in types provided by the language | Constructed using one or more primitive types |
| Complexity | Simple and straightforward | More complex in structure and behavior |
| Examples | int, float, bool, char | array, struct, class, pointer, union, enum |
| Storage | Typically occupy a single memory location | May span multiple memory locations depending on structure |
| Manipulation | Supports basic, direct operations defined by the language | Enables complex data manipulation through user-defined operations |
| Mutability | Usually immutable (value cannot be changed once assigned) | Often mutable (internal content can be changed after creation) |
Abstract Data Types
An Abstract Data Type (ADT) is a conceptual model that defines a data structure in terms of its behavior—i.e., the operations that can be performed on it—without specifying the details of its implementation. It focuses on what operations are to be performed, rather than how they are implemented. ADTs provide an abstraction that hides the internal structure and implementation details from the user.
Key features of Abstract Data Types include:
- Abstraction: Users only need to understand the available operations, not the internal workings.
- Better Conceptualization: ADTs model real-world entities more effectively.
- Robustness: Programs using ADTs are better equipped to handle errors.
- Encapsulation: Internal details are hidden, and only a well-defined interface is exposed for interaction.
- Data Abstraction: Implementation details are abstracted away, allowing a focus on functionality.
- Data Structure Independence: The same ADT can be implemented using different underlying data structures, such as arrays or linked lists.
- Information Hiding: Access is controlled to maintain data integrity and prevent misuse.
- Modularity: ADTs can be composed to form more complex structures, enhancing reusability and organization.
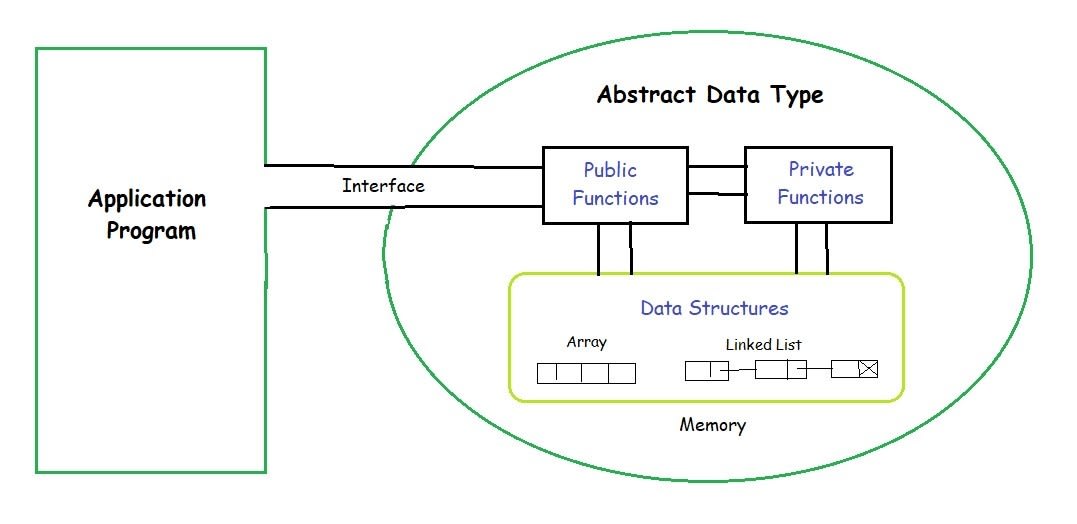
This image illustrates how an ADT exposes only the necessary interface to the application program while hiding internal structures like arrays and linked lists through private functions.
Advantages:
- Encapsulation: Simplifies maintenance and evolution of data structures.
- Abstraction: Reduces complexity for the end user and minimizes the chance of errors.
- Data Structure Independence: Enhances flexibility in implementation and optimization.
- Information Hiding: Safeguards data from unintended access or modification.
- Modularity: Facilitates the construction of complex systems from simpler components.
Disadvantages:
- Overhead: Abstraction layers may introduce additional memory and processing costs.
- Complexity: Designing and implementing ADTs can be challenging, especially for intricate data structures.
- Learning Curve: Understanding and using ADTs effectively requires foundational knowledge.
- Limited Flexibility: Some ADTs may not be suitable for every use case or data type.
- Cost: Development and maintenance of ADTs can require more time and resources.
Need for Data Structures
Data structures are fundamental for efficiently organizing and managing data in computer programs. They provide methods for storing, retrieving, and manipulating data in ways that optimize operations such as insertion, deletion, searching, and updating. Selecting the appropriate data structure for a specific task can greatly enhance a program’s performance and overall efficiency.
-
Efficient Data Management:
- Organization and Storage: Data structures offer systematic ways to store and organize data, making access and manipulation straightforward.
- Handling Large Datasets: They are essential for managing large volumes of data efficiently, as used in systems like databases and search engines.
- Performance Optimization: The right data structure improves the performance of both algorithms and programs by reducing computational complexity.
-
Enhancing Algorithms:
- Algorithm Design: Data structures serve as the foundation for designing efficient algorithms.
- Problem-Solving: They enable developers to solve complex problems by offering efficient methods to manage and operate on data.
-
Real-World Applications:
- Databases: Data structures underpin database systems, allowing for fast data storage and retrieval.
- Operating Systems: Used in areas such as memory management, file systems, and scheduling.
- Search Engines: Crucial for indexing and searching through vast amounts of text data.
- Machine Learning: Enable the storage and processing of large datasets required for model training and prediction.
- Web Browsers: Used to represent web pages (e.g., the DOM) and manage internal browser data efficiently.
-
Improving Code Quality:
- Readability: Appropriate data structures can make code cleaner and easier to understand.
- Scalability: They allow applications to scale effectively with increasing data volume and complexity.
- Abstraction: Provide a higher-level interface to interact with data, abstracting the lower-level implementation details.
Types of Data Structures
The choice of data structure depends on the operations required and the algorithms to be applied. Common data structures include:
-
Array: A linear data structure consisting of elements of the same type stored at contiguous memory locations.
- Random Access: Elements can be accessed in constant time (O(1)) due to fixed-size storage and a known base address.
- Cache Friendliness: Contiguous storage benefits from spatial locality, enhancing performance.
-
Stack: A linear structure following the Last In First Out (LIFO) principle. Data is added (pushed) and removed (popped) from the same end.

-
Queue: A linear structure that follows the First In First Out (FIFO) principle. Data is added at one end (rear) and removed from the other (front). Example: queues of users waiting for service.

-
Linked List: A linear structure where elements (nodes) are stored in non-contiguous memory locations and linked using pointers.

-
Tree: A non-linear, hierarchical structure with a root node and child nodes. In a tree, the topmost node is called the root node. Each node contains some data, and data can be of any type. It consists of a central node, structural nodes, and sub-nodes which are connected via edges. Trees allow efficient searching, sorting, and hierarchical data representation.

-
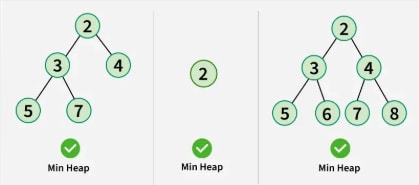
Heap: A specialized binary tree that satisfies the heap property: in a min-heap, each parent node is less than or equal to its children. Heaps are often used to implement priority queues.
-
Graph: A non-linear structure consisting of vertices (nodes) connected by edges. Useful in modeling networks, social graphs, and solving complex algorithmic problems.

-
Trie: A tree-like structure used to store dynamic set of strings, particularly useful for prefix-based searches. It allows for efficient retrieval and storage of keys, making it highly effective in handling large datasets. Supports fast insertion, search, and deletion of words.

-
Hash Table: A structure that stores key-value pairs using a hash function to map keys to indices. Allows for average-case constant time (O(1)) insertion, deletion, and lookup.

Data Structure and Algorithms
Data Structure and Algorithms Structure HPTU BTech CSE Syllabus
Algorithm
Definition, characteristics, development of algorithm, Analysis of complexity - time complexity, space complexity, order of growth, asymptotic notation with example, obtaining the complexity of the algorithm.